
Is polyamory a single, global web of love?
Polyamory is a relationship style where people engage in multiple, committed, romantic relationships at the same time. In the West, more and more people who practice it have been coming together in communities arranged roughly by country. A good resource for people who want to know more is Franklin Veaux’s website.
In this post, I do not talk about polyamory per se. Rather, I want to remark on the insights you can get if you think about it as a social network. Each polyamorous person is a node in the network. Nodes are connected by edges, encoding the romantic relationships across people. Now, in 1959, Paul Erdös and Alfred Rényi wrote a famous graph theory paper. Among other results, they proved that:
- If you take a network consisting of a number of disconnected nodes;
- And then start adding one link at a time, each edge connecting any two nodes picked at random, then;
- When the number of links of the average node exceeds 1, a giant component emerges in the network. In a network, a component is a group of nodes that are all reachable from each other, directly or indirectly. A giant component is a component that consists of a large proportion of all nodes in the network. If a network has a giant component, most of its nodes are reachable from most other nodes.
Almost by definition the average polyamorists has more than one relationship. Granted, some people will only have one: maybe they are monogamous partners of a polyamorous person, or maybe they are still building their own constellation. Ther are even people who identify as polyamorous but are currently single. But there is also quite a high proportion of people with two or more partners. So, under most real-world conditions, the number of partners of the average person in the polyamory community is greater than one.
So, we have a mathematical theorem about random graphs and an educated guess about polyamory. When we put the two together, we obtain a sweeping hypothesis: most polyamorists in the world are connected to each other by a single web of love. Everyone is everyone else’s lover’s lover’s lover’s lover – six degrees of separation, but in romance. This would be an impressive macrostructure in society. Is it really there? There is a missing paper here. How to disprove the hypothesis and write it?
A statistical physics-ish approach
The hypothesis is quite precise, and in principle testable. But there are are substantial practical difficulties. You’d need unique identifiers for every poly person in the world, to make sure that Alice, Bob’s lover, is not the same person as Alice, Chris’s lover. Some people perceive a stigma around polyamory, and even many of those who don’t prefer to keep their relationship choices to themselves. So, the issues around research ethics, privacy and data protection are formidable.
So, maybe we can take a page out of the statistical physics playbook. The idea of statistical physics is to infer a property of the whole system (in this case, the property is the existence of a giant component in the polyamory network) from statistical, rather than deterministic, information on the system’s components (in this case, the average number of partners per person). In our case, you could:
- Build computer simulations of polyamorous networks, and see if, for a realistic set of assumption, there is a value of the average number of relationships R that triggers a phase transition where a giant component emerges in the network.
- Run a simple survey (anonymous, sidestepping the ethics/privacy/data protection problems) to ask polyamorists how many relationship they have. Try also to validate assumptions underpinning your simulations.
- Compare the average number of relationships R’ as it results from the survey with the trigger value R as it results from the simulation. If R’>R, then most polyamorists are indeed connected to each other by a single web of love.
In the rest of this post, I am going to think aloud around step 1. At the very end I add a few considerations on step 2.
The model
Models are supposed to be abstract, not realistic. But the assumptions behind the Erdös-Rényi random graph model (start with disconnected nodes, add edges at random) are a bit too unrealistic for our case. I tried to build my own model starting from a different set of assumptions:
- I assume that, as is often the case in real life, people move into polyamory by opening their previously monogamous relationships. So, I start from a set of couples, not of individuals. In network terms, this means starting with a network with N nodes, organized into N/2 separate components with 2 nodes each. N/2 is also the number of edges in the initial network.
- At every time step, I add an edge between two random individuals that are not already connected. We ignore gender, and assume any person can fall in love with any other person.
Notice that, at time 0, all nodes of the network have one incident edge. In an Erdös-Rényi graph, we would already see a giant component, but this is not an Erdös-Rényi graph. In fact, we can think of it in a different way: we can redefine nodes as couples, rather than individuals. This way, we obtain a completely disconnected network with N/2 node. As we add edges in the original network of individuals, we now connect couples; and we are back into the Erdös-Rényi model, except with N/2 couples instead of N individuals. By the 1959 result, a giant component connecting most couples emerges when the average couple has over one incident edge: in other words, when there are N/4 inter-couple edges (since one edge always connects two couples, or, more precisely, two people in two different couples).
How many edges do individual people have on average at this point? There were N/2 intra-couple edges at the beginning; we then added N/4 inter-couple new ones. This means our network has now N x 3/4 edges. Each edge is incident to two individuals; so, the average individual has 1.5 incident edges.
Let us restate our result in polyamory terms.
Start from a number of monogamous couples. At each time period, add a new romantic relationship between two randomly chosen individuals that are not already in a relationship with each other. When the average number of relationships exceeds 1.5, a large share of individuals are connected to each other by an unbroken path of romantic relationships.
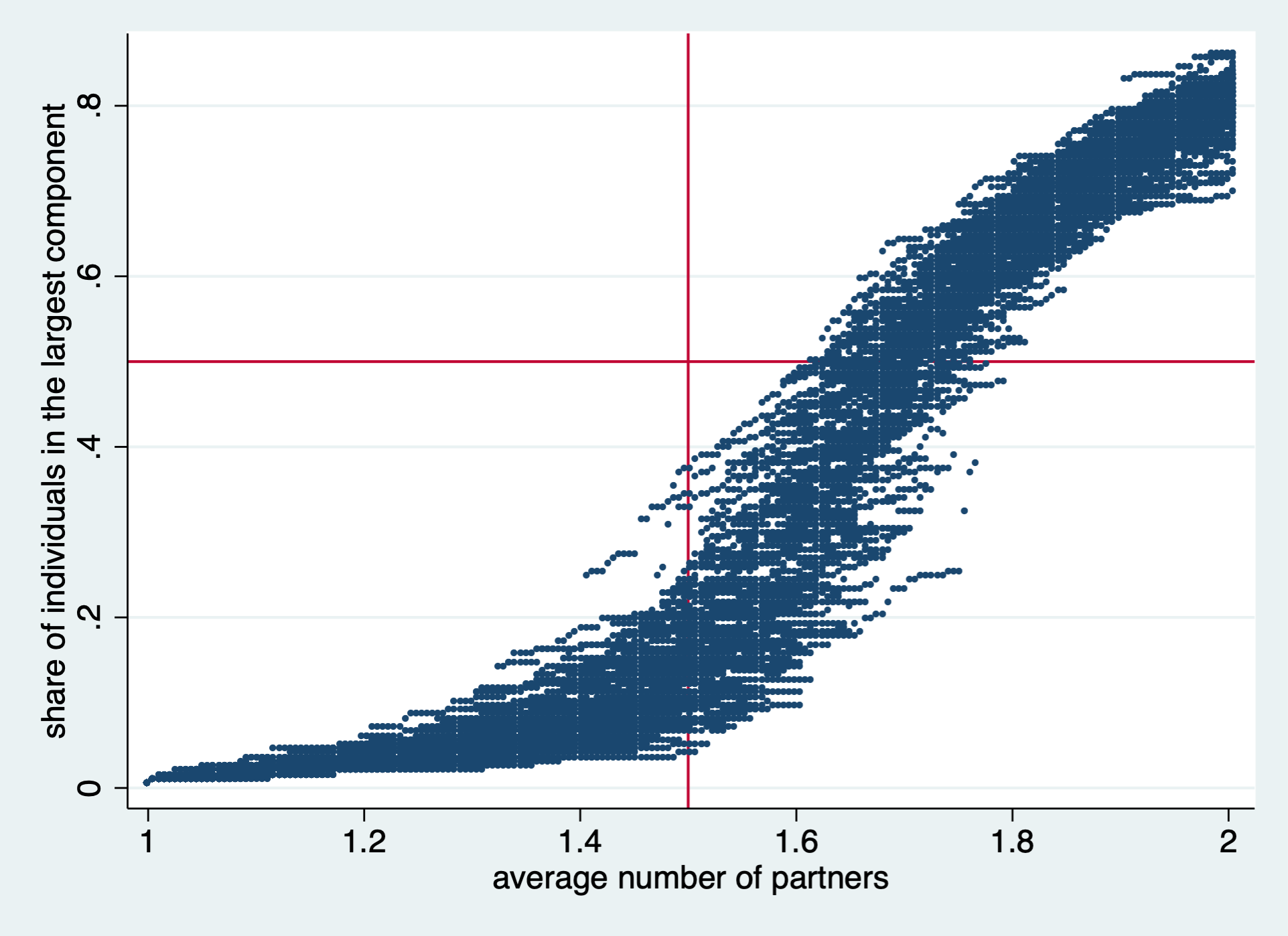
I have created a simple NetLogo model to illustrate the mechanics of my reasoning. You are welcome to play with it yourself. Starting from a population of 200 couples (and ignoring gender), and running it 100 times, I obtain the familiar phase transition, with the share of individuals in the largest component rising rapidly after the average number of partners per person crosses the 1.5 threshold. The vertical red line in the figure shows the threshold; the horizontal one is drawn at 0.5. Above that line, the majority of individuals are in the “one love” giant component. Notice also that, when the average number of partners reaches 2, about 80% of all polyamorists are part of the giant component.
Obtaining data
Now the question is: do polyamorous people actually have over 1.5 relationships on average? Like so many empirical questions, this one looks simple, but it is not. To answer it, you first have to define what “a relationship” is. Humans entertain a bewildering array of relationships, each one of which can imply, or not, romance (and how do you even define that?), sex, living together, parenting together, sharing finances and so on. They differ by duration, time spent together per week or per year, and so on. Coming up with a meaningful definition is not easy.
Supposing you do hammer out a definition, then you have to get yourself some serious data. Again, this is difficult. To quote the authors of the 2012 Loving More survey:
Truly randomized surveys […] are difficult, if not impossible, to obtain among hidden populations.
And, sure enough, I have been unable to find solid data about the average number of partners in polyamorous individuals.
The Loving More survey itself, for all its limitations, is one of the richest sources of empirical data on human behavior in polyamory: it involved over 4,000 Americans who self-identify as polyamorous. But the question “how many relationships do you have” was not asked. We do know that respondents reported an average of 4 sexual partners in the year previous to the survey. The exact same question is also asked in the (statistically legit) General Social Survey: there, a random sample of the U.S. population reported 3.5 sexual partners on average during the year previous to the survey. The difference is statistically significant, but it is not large, and anyway it only refers to recent sexual partners. Frankly, I have no idea how to infer values for the average number of romantic relationships from these numbers.
So, there is a significant empirical challenge here. But, if you solve it, you get to write the missing paper on polyamory, with the exciting conclusion that the “one love global network” exists, or not. I am looking forward to reading it!
Photo credit: unknown author from this site (Google says it’s labelled for reuse)
