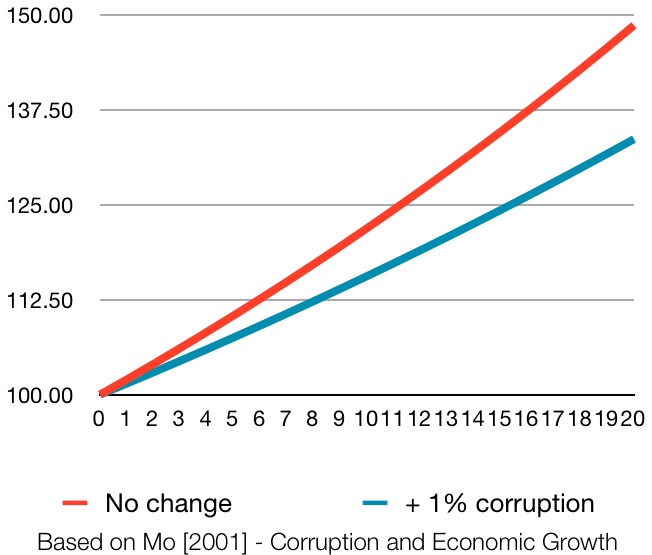
Se abiti in Italia e sei curioso di quanto e come spende (e tassa) il tuo Comune, è il tuo giorno fortunato. Dalla settimana scorsa, OpenBilanci pubblica in rete i dati finanziari dettagliati degli ultimi dieci anni su tutti gli 8,092 comuni italiani. Sono disponibili sia i dati di preventivo che quelli di consuntivo, così come indicatori di performance come autonomia finanziaria e velocità di spesa. Non solo tutti i dati sono in formato aperto e scaricabili: Open bilanci ha anche un’elegante interfaccia web per l’esplorazione preliminare dei dati. Interfacce simili si trovano anche in altri progetti open data italiani, come l’ammiraglia OpenCoesione, che espone dati di spesa su 749,112 progetti finanziati dalle politiche di coesione. Questo non sorprende: OpenCoesione è un progetto pubblico, OpenBilanci è nonprofit, ma la stessa squadra di sviluppatori visionari li ha montati entrambi, usando a volte un’associazione, altre volte un’impresa.
Nello spazio di pochi anni, i dati aperti sono diventati una forza formidabile per l’apertura, la trasparenza e perfino la data literacy in un paese che ha molto bisogno di tutte e tre. Funzionari pubblici lungimiranti in alcune Regioni (e qualche città) lavorano ormai normalmente insieme ai civic hackers: OpenBilanci è stata finanziata dalla Regione Lazio attraverso la sua politica per l’innovazione rivolta alle PMI, mentre l’Emilia-Romagna ha costruito una solida alleanza con la più grande comunità italiana civic hacker, Spaghetti Open Data. Con una mossa elegante, la città di Matera ha deciso di ospitare sul proprio portale open data anche , purché aperti, e così incoraggia una cultura del dato aperto.
Quando le autorità pubbliche non cooperano, i civic hackers italiani semplicemente si aprono i dati pubblici da soli. Uno dei miei progetti preferiti in questo campo è Confiscati bene, nato durante un epico hackathon di Spaghetti Open Data. Il gruppo ha scritto un programma per scaricare tutti i dati (non aperti) contenuti sul sito dell’Agenzia Nazionale per i Beni Sequestrati e Confiscati alla criminalità organizzata. Li ha ripuliti, georeferenziati, resi scaricabili, costruito una bella interfaccia web di esplorazione, messi su un elegantissimo sito nuovo di zecca e regalato il tutto a ANBSC. Anche OpenBilanci è stato costruito a partire dallo scraping di oltre due milioni di pagine web.
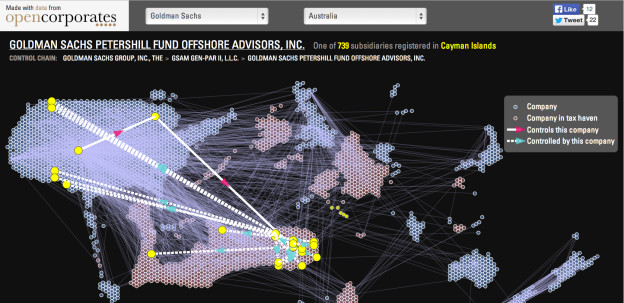
La scena italiana è quella che conosco meglio, ma progetti open data interessantissimi appaiono dovunque. Il mio preferito in assoluto è inglese: OpenCorporates raccoglie dati su oltre 60 milioni di imprese di tutto il pianeta. Usando identificatori unici e informazioni sugli assetti proprietari, OpenCorporates porta un po’ di luce sul mondo delle imprese, che ha molti meno obblighi di trasparenza del settore pubblico. Questa visualizzazione interattiva basata su OpenCorporates, per esempio, vi insegnerà molto su Goldman Sachs.
Il movimento open data, pare, è diventato grande. È successo molto in fretta: in meno di quattro anni siamo passati da ristretti circoli di nerd che si entusiasmavano per il discorso “raw data now” di Tim Berners-Lee a una comunità forte e numerosa (siamo quasi mille sulla mailing list di Spaghetti Open Data, e maciniamo una media di venti messaggi al giorno, 365 giorni all’anno) e una falange di giovani decisori che conoscono il tema e sono a stretto contatto con la community. Sono orgoglioso di voi, sorelle e fratelli d’arme. E il meglio deve ancora venire: probabilmente verrà quando ci riuniremo da tutta Europa, e sono sicuro che succederà presto perché i tempi sono maturi. Chissà, la cultura dei dati potrebbe perfino riuscire a spostare la politica europea dalla retorica populista al dibattito basato sui fatti.