
During the summer, the Wikitalia group worked hard to improve Edgesense, the tool for real-time network analysis we are building as a part of the CATALYST project. As we worked on out “official” test bed community, that of Matera 2019, I happened to tell about it to Salvatore Marras. He proposed to deploy Edgesense on Innovatori PA. Edgesense is a very raw alpha, but the curiosity of trying it on a much larger community han the one in Matera (over ten thousand registered users) made us try anyway.
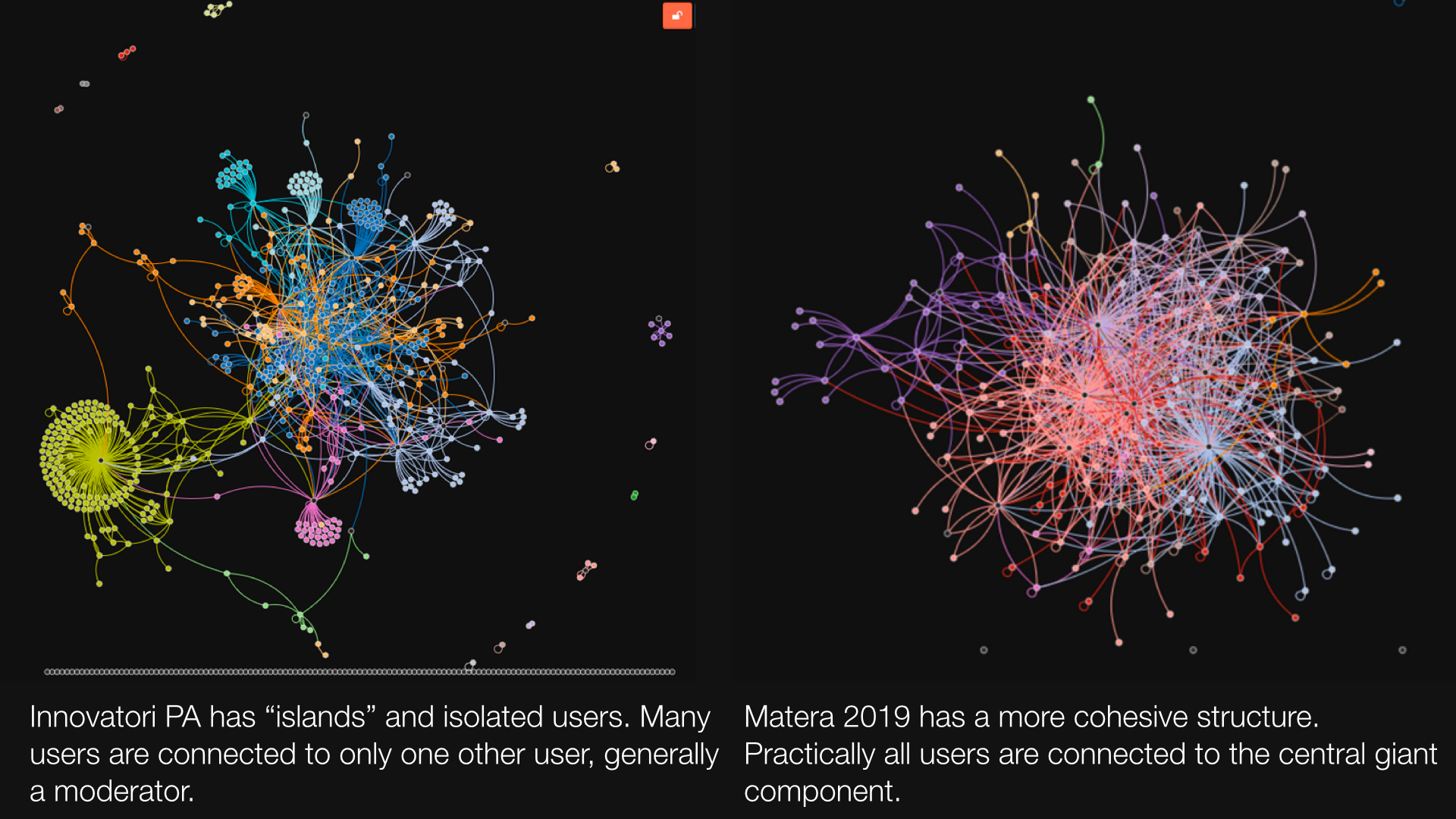
Surprise:despite using the same software as Matera 2019 (Drupal 7), Innovatori PA is not just bigger: it is really different. Even greater surprise: Edgesense allows you to literally see the difference with the naked eye (click here for a larger image with an English caption).
Metrics confirm what the eye sees. Innovatori PA, with over 700 active nodes (active means they wrote at least one post or one comment), gives rise to a rather sparse network with only 1127 relationships. Average distance is quite high, 3.76 degrees of separation (Facebook, with a billion-plus users has only 4.74 – source); modularity, the simplicity with which the networks partitions into subcommunities, is very high.
Conversely, the Matera 2019 community gives rise to a quite dense network: 872 relationships, so 80% of those in Innovatori PA, but with fewer than a third of its active users. Degrees of separation are 2.50, and modularity much lower.
If you want to play with Edgesense – among other things it helps to see the growth of the network over time – go here for Matera2019. No need to install anything, you access it with your browser. I recommend the tutorial we prepared to teach basic network analysis for online communities (click on the “tutorial” link top right in the page. The Innovatori PA installation is still being tweaked; I will update this post as it becomes available.
{kind=link}