
My brothers- and sisters-in-arm of Ondata have been exploring ways to use LLMs to facilitate their interactions with online sources of open and statistical data. In so doing, they have hit on a working style that I find very promising.
The obligatory disclaimer: I do not endorse “artificial intelligence”, a highly controversial socio-technological construct. As an economist, I am irked by the economic aspects of the tech: the insane concentration indices in this industry, the information asymmetries, the gigantic losses associated with the expansion of its customer base, its “dogshit unit economics”, to quote Ed Zitron, its massive environmental and social costs, its dark politics that makes it gravitate towards disinformation and deepfakes. I could go on, but you get the idea. This is probably preaching to the choir anyway, given that most people I hang out with are very skeptical of anything that smacks of “AI”.
And yet, Andrea Borruso and Matteo Fortini (among, undoubtedly, many others) have proposed an approach that I quite like. It goes like this: if you ask a data-related question to a LLM, such as “is the unemployment rate in Guatemala growing faster or slower than that in Ethiopia?”, you get better than even odds that the LLM will just make something up. A more reliable approach is to download the pertinent data from an authoritative source, and see for yourself. Andrea and Matteo, as honoured elders in the Italian open data community, are no strangers to tracking down data warehouses, poring over API documentation, building structured queries and feeding the result of those queries to scripts that will tease answers out of the data. And their substantial experience tells them, inequivocally, that having to do this work every time you want a question asked sucks big time.
But they found an alternative: codifying their deep knowledge of structured data and structured metadata in ways that are legible to an LLM. Then, instead of asking the LLM the direct question, they can instruct it to look up the data at the source – say, the World Bank’s data warehouse. This is possible because, after 20 years of open data movement, authoritative data to address many of those questions exist, and are structured. For example, there exists an ISO standard for machine-to-machine exchange on statistical data, called SDMX and followed by many statistics agencies. So, Andrea built OpenSDMX, a command-line interface that interacts with SDMX-compliant data sources. Give it a search term (unemployment rate Guatemala), and it will search the catalog, find the relevant datasets based on the metadata, and return a menu of options of what to download. For example, do you only want to know the most recent estimate of the unemployment rate, or would you like a time series? If sub-national data are available, do you want them too? Perhaps a disaggregation by sex, or age group? And so on.
OpenSDMX works well on its own, but it was set up so that you can interact with it via any LLM. This is done via something called a skill, which is a human-readable file containing the instructions necessary to use the command line interface well. To a human it reads like good documentation: to a LLM it is a long, detailed, well structured prompt. Thanks to it, LLMs can turn the instructions of their human operator into a structured flow of interactions with SDMX-compliant data sources by means of well-formed SDMX queries – there is no need to guess, because the skill contains correct, unambiguous structures written and validated by someone like Andrea and Matteo, who knows the standard well. Further specifications of the skill (more text files) address the quirks not disciplined by the SDMX standard itself. For example, while EUROSTAT (the European Union’s statistics agency) and ISTAT (Italy’s) both comply with SDMX, the former labels its variables in lowercase, and the latter in uppercase. This is the type of quirk known for causing lots of mild irritation to data scientists: having it encoded in the skill means your LLM benefits from the experience of veteran data scientists, even if you do not bother to read the skill.
The approach works not only for statistical data, but for any kind of data and metadata as long as they are exposed according to a standard. Another conceptually similar project built by Andrea is a Model Control Protocol (MCP) server to interact with open data portals and their content. This is possible, again, because the information therein is structured according to well-documented standards. Most open data portals are built on CKAN, and the datasets hosted therein follow another standard, DCAT. The logic is the same: open data portals are somewhat standard, and over the years the community has produced lore about how to whisper to them so that they will return the data we want. Encode that lore into text files that an LLM can interpret as a prompt. Then use the LLM as a natural-language interface to the data.
In social and economic research, it happens quite often that you have a hunch that can, in principle, be validated, or disproven, by looking at data. Andrea’s and Matteo’s approach greatly reduces the distance between formulating a question and getting an initial answer. It is even more useful when you have not a question, but a hunch, and you want to get an initial look at the raw data to see if you are even remotely right.
I decided to test OpenDMX as a way to validate or invalidate a conjecture. My conjecture was:
Within the European Union, Eastern European member states are undergoing more economic upheaval than average.
I wanted to test this conjecture by comparing the rates of business creation and business destruction (as captured by the creation of new companies and the cessation of existing ones). Furthermore, I want to do it by looking at sub-national-level data, if they exist. The idea is that upheaval is in the extremes, not in the averages: I am looking at the location of regions where business creation and destruction are unusually fast. To be clear, this is a completely unfounded conjecture, but it is a conjecture of the kind that economists make all the time, so it is valid as a test.
I launched an LLM and called up the skill, then wrote a prompt:
> /sdmx-explorer
> Business creation and business cessation rates in European Union
countries, geographically disaggregated This gets me:
I have found the primary datasets on Eurostat that cover business creation
(births) and cessation (deaths) with regional disaggregation.
The most relevant dataset is BD_SIZE_R, which provides comprehensive business
demography data down to the NUTS 3 region level (the most granular regional
level in the EU, roughly equivalent to provinces or counties).
Candidate Datasets
1. BD_SIZE_R — Business demography by size class and NUTS 3 region ⭐
Recommended
* Coverage: All enterprises (including those with no employees).
* Key Indicators: Number of births, number of deaths, birth rate (%),
death rate (%), and net growth rate.
* Dimensions: Region (NUTS 3), economic activity (NACE Rev. 2), and size
class.
* Timeframe: Typically annual data.
[...]
How would you like to proceed?
- Would you like to explore BD_SIZE_R (all enterprises) or focus on
employer-only data?
- Do you want to see the specific regions or economic sectors (NACE)
available?
- Are you interested in a specific year or a recent comparison?
Good to know I can make a sectorial analysis by NACE codes, but no need to make this complicated right now. I want to see if there are macro differences between regions. For the same reason, I am not going to go into dynamic analysis, just get a snapshot. If I don’t see anything there is probably nothing to see, and then no point splitting hairs by doing sophisticated analysis on barely perceptible phenomena. So:
> Use BD_SIZE_R at NUTS 3 disaggregation. For each NUTS3 region, get birth and
death rate. Write to console the URL to the original query for verification
purposes. Next, create a scatterplot where each NUTS3 region is a point. Put
birth rates on the Y-axis and death rates on the X-axis. Do not label
datapoints for legibility. Color-code them according to macro-region:
Western, Northern, Eastern and Southern Europe. In the legend, provide a
list of the countries included in each region.And I got:
I have completed the analysis of business birth and death rates across
European NUTS 3 regions.
Verification URL
You can verify the original query and data structure directly on the Eurostat
portal:
https://ec.europa.eu/eurostat/databrowser/view/BD_SIZE_R/default/table?lang=en
(https://ec.europa.eu/eurostat/databrowser/view/BD_SIZE_R/default/table?lang=e
n)
European Macro-Regions (Legend)
The scatterplot color-codes regions based on the following grouping:
* Western Europe: Austria (AT), Belgium (BE), France (FR), Germany (DE),
Ireland (IE), Luxembourg (LU), Netherlands (NL), Switzerland (CH)
* Northern Europe: Denmark (DK), Estonia (EE), Finland (FI), Iceland (IS),
Latvia (LV), Lithuania (LT), Norway (NO), Sweden (SE)
* Eastern Europe: Bulgaria (BG), Czechia (CZ), Hungary (HU), Poland (PL),
Romania (RO), Slovakia (SK)
* Southern Europe: Croatia (HR), Cyprus (CY), Greece (EL), Italy (IT), Malta
(MT), Portugal (PT), Slovenia (SI), Spain (ES)
Results Summary
* Data Source: Eurostat BD_SIZE_R (Business demography by size class and NUTS
3 region).
* Indicator: Birth rate (ENT_BRTHR_PC) and Death rate (ENT_DTHR_PC).
* Geographic Detail: NUTS 3 disaggregation (counties/provinces).
* Latest Data: Most regions reflect data from 2021 or 2022.
The generated scatterplot scatter_demografia_final.png shows the correlation
between business creation (Y-axis) and cessation (X-axis). Regions along the
diagonal have a stable business population, while those above the diagonal are
growing and those below are experiencing a net contraction in the number of
active enterprises.
After some beautification I got a scatterplot that tells the story I was looking for.
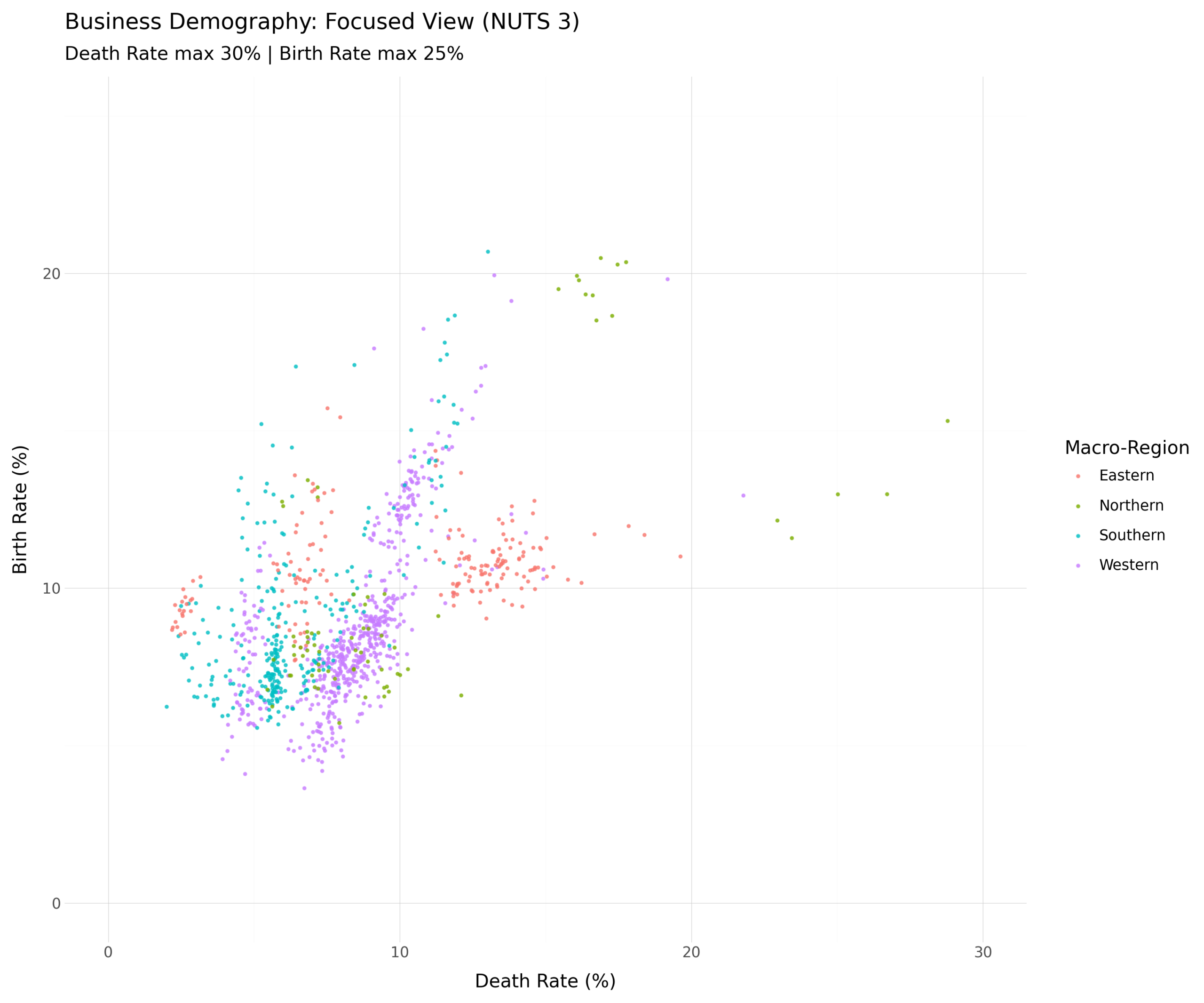
My hunch, it turns out, is not supported by the data. If anything, it is northern regions in the EU that are experiencing a high churn. Those green dots towards the right of the chart represent Estonian territories, with a Finnish one that is an outlier and not even shown. But this is not the point here. The point is this: investigating this hunch required me to think like an economist. I can formulate a testable hypothesis. I know what economic data can and cannot say. I have learned to stay away from overinterpreting them. The LLM here thinks like a data scientist, borrowing Andrea’s expertise. It knows how to look inside the EUROSTAT data warehouse, read its labels, and build well-formed queries in SDMX format. It also has access to Python libraries for simple data visualizations. This means that, in minutes, I can get to a very rough test of my hunch.
That makes me a centaur. I am borrowing the word from Cory Doctorow. He thinks that LLMs can be used to empower humans to do better and faster things that humans do, or, viceversa, to boss over humans so that LLMs themselves can do things that they themselves cannot do. In the first case, the composite of human and machine is a centaur, a human being running around with the strength and speed of a machine. In the second, it is a reverse centaur, where the human part of the composite is a meat appendage to the machine making all the decisions, or an accountability sink, there to take the blame for when the LLMs screw up. I am a centaur here, whereas an Amazon delivery driver is a reverse centaur, with the machine part micromanaging the human and forcing him to pee in a bottle so as to squeeze the last cent of value from his labour.
Since well before LLMs, the open data movement believes that, by taking care of data (collecting them with intent, documenting them, publishing them with open license, creating tools that people can use to access and process them), you could empower people to do more. An important category of people that we cared about empowering are journalists, researchers, activists: whoever needs knowledge to make a difference. These new LLM-compatible tools come from this lineage. An investigative journalist can now type a natural-language question, such as “which datasets do we have about flood damage in Latin America?”, and the CKAN MCP server will trigger a series of queries that will look for CKAN-powered open data portal, and then look within their catalogs for appropriate datasets. It will even do this independent of the language that the journalist is typing in, and that the datasets are documented in.
Needless to say, none of this is possible if data are not curated, documented, published in machine-readable format, following open standards, with good metadata. In other words, none of this is possible if we do not treat the data as a digital public good, and do the work of documenting and publishing in the interest of those that will come after us. That is not easy to do, and even public sector organizations will in general not do it in the absence of firm policies.
But when it is done, it can be incredibly empowering. Ukrainian open data activist Nadiia Babynska Virna reports using Andrea’s CKAN MCP server in combination with a locally-run LLM to check the openness of public sector information with no code and only basic data science skills, “in the middle of a war”. Centaur. Conclusion: while my hunch about the geography of economic upheaval was unfounded, Doctorow’s own centaur/reverse centaur model holds. In his words, it’s not what the technology does, it’s who the technology – and, I would add, the data – is for, and who it is done to.