A large part of the economy deals in knowledge – and I’m not talking about education alone. Knowledge is a major ingredient, as well as a byproduct of, any credible attempt at societal change. A host of institutions – universities, governments, parliaments, think tanks and what have you – continuously produce knowledge. Much of that is codified into reports and other publications, which are then made available for download from their respective websites.
However, many reports are rarely read. A famous 2014 World Bank study found that about a third of their reports received zero downloads. This does not mean no one reads them, but it does highlight how difficult it is for non-intended readers—like researchers or practitioners in related fields—to find them. The current system is low in serendipity. Additionally, as websites change, old URLs break, resulting in 404 errors and lost access to content. This phenomenon is known as “link rot”.
We can do better. Academia has faced the challenge of serendipitous knowledge reuse for centuries. Over the past thirty years, it has built a robust ecosystem by leveraging the digital revolution and the power of open standards and open licenses. If your work includes producing reports and publications for public consumption, you too can adopt these practices to make them more discoverable and reusable, increasing their impact.
Unique identifiers enable a digital ecosystem of services
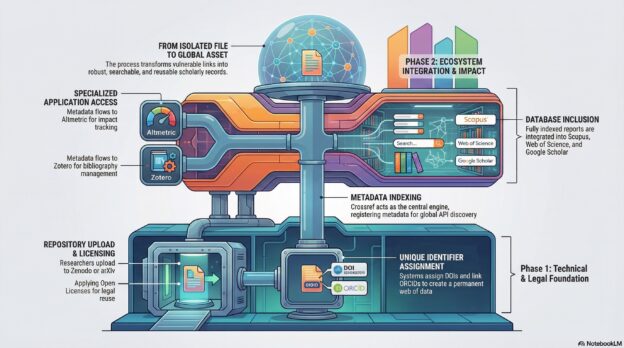
At the heart of this ecosystem are Digital Object Identifiers (DOIs). A DOI uniquely identifies any file—article, report, dataset, or executable application. DOIs are an ISO standard, issued by Registration Agencies that maintain metadata (authors, year, organisation, keywords, etc.) in interoperable databases. The largest is Crossref, a consortium of 23,000 publishers, currently handling two billion API requests per month. In a similar way, authors are uniquely identified by ORCID – Open Researcher and Contributor ID. ORCID provides an open, API-accessible database of researchers, automatically updated as new papers are uploaded. DOIs and ORCIDs create a web of linked data: papers link to their authors, and authors link back to their works.
These open, machine-readable datasets of uniquely identified knowledge products and authors have enabled a rich ecosystem of services. Repositories like arXiv, Mendeley and Zenodo allow researchers to upload papers and assign DOIs. Applications like Altmetric index documents in these repositories to measure their impact by tracking citations and aggregating them into bibliometric indicators. These, in turn, influence inclusion in major academic databases, such as Web of Science, Scopus, Lens and Google Scholar.
Academic repositories accept papers before they get peer reviewed (“preprints”), acknowledging that some knowledge is at most useful when its fresh, and academic review processes typically takes months. So, knowledge products from non-academic organizations (like NGOs) and academic research papers have become interoperable, part of the same digital space. The research community has come to read and cite reports more often, and this adds to their serendipity and impact. UNDP and other organizations could even take advantage of this to curate their own series and even journals, displaying content from repositories via API and experimenting with forms of review and curation. The European Commission’s Open Research Europe is an example of this model. These innovations, and others that will come, are enabled by community-created software libraries to access Crossref’s APIs, for example for Python and R.
The ecosystem includes bibliography management applications like Zotero. Instead of manually creating a bibliography for every publication, researchers maintain libraries of works they cite, from which these applications create bibliography on the fly. Such applications download metadata from Crossref and transform them into citations and bibliographies in any format, via plugins for LaTeX, Word, Google Docs, Obsidian and other editing applications.
Legal interoperability unlocks the power of open
The digital revolution enables remixing and cross-referencing from a technical perspective, but legal barriers remain. Knowledge products are governed by intellectual property rights (IPRs), which by default restrict many uses. Licenses specify what can and cannot be done. For example, Google Maps data is not open. This means that you can use Google Maps as a service, but you are not allowed to do anything else with the data. Say you use Google Maps to obtain the coordinates of UNDP’s offices around the world and put the coordinates in a CSV file. Although you knew the locations of the offices and have produced the file, the fact of having used Google Maps to find out the coordinates entangles your file with Google’s IPRs. You cannot publish it without calling in the lawyers.
To be truly frictionless, knowledge products must be both technically and legally open: irrevocably cleared by their copyright holder for use, redistribution, modification, and remixing by all, as per the open definition. This is crucial for datasets, as researchers avoid data with legal hurdles. Failing to use open licenses limits the spread, and therefore the impact, of your work. If you have a say in crafting your organization’s policies on licensing its own content, I would recommend you push for an explicit and blanket authorization to publish using open licenses, like those provided by Creative Commons.
Publish for frictionlessness
To wrap up, here’s some recommendations for publishing reports and publications.
- Use Zenodo as a long-term repository. It provides free DOIs, supports versioning, and is run by CERN, ensuring reliability.
- Obtain a (free) ORCID for each author or contributor and include them in the metadata. Zenodo supports multiple contributor roles, such as “team leader” and “data curator”.
- If your report is based on data you collected, publish the dataset separately with its own DOI and cite it in the report. Publishing open data is nontrivial; see a detailed guide to do that.
- Use open licences, such as Creative Commons Attribution 4.0 International (versions 4 and above protects your readers from copyleft trolling), which is widely used and protects both creators and users.
- Link your website’s report page to Zenodo for downloads to centralise page views and download statistics.
- Consider using bibliometric services such as Altmetric to track your impact over time.
Image made by Notebook LLM, based on the text of the post and a prompt written by myself.